Enterprise-Grade Agentic Setup: Warum ein API-Key keine KI-Strategie ist

TL;DR: „Vibe Coding mit API-Key ist Kindergarten. Enterprise-Grade heißt: spezialisierte Sub-Agents, sauber dokumentierte TOOLS.md, dedizierte System Prompts und Tool-Loading pro Session – damit Agents schnell, billig und mit Zugriff auf reales Operations-Wissen antworten. Ohne diesen Stack ist KI im Unternehmen nutzlos."
— Till FreitagDie Zone, über die in der Öffentlichkeit niemand spricht
Es gibt einen Bereich der KI-Adoption, der in der Öffentlichkeit konsequent ignoriert wird. Nicht weil er unwichtig ist – sondern weil er unsexy und technisch ist.
- Einen API-Key zu einem Frontier-Modell in deine Website kleben? Kinderkram.
- Einen Chatbot mit System Prompt und Vector Store bauen? Demo-Niveau.
- Ein agentisches Setup, in dem Sub-Agents Zugriff auf dein operatives Wissen haben, blitzschnell antworten, mit sauberer
TOOLS.mdund dedizierten System Prompts arbeiten – und ein Agent oder ein User Antworten von einem anderen Agent bekommt? Das ist der Wert.
Der Sprung von "Vibe Coding mit OpenAI-Key" zu "Enterprise-Grade Agentic Setup" ist nicht graduell – er ist kategorisch. Ohne diesen Sprung ist KI in deinem Unternehmen effektiv nutzlos. Mit ihm automatisiert sie dein gesamtes Operations-Geschäft.
Warum ein API-Key allein keine Strategie ist
Die meisten Unternehmen, die wir in den letzten 18 Monaten gesehen haben, sind in einer dieser drei Phasen stecken geblieben:
| Phase | Symptom | Realer Business-Wert |
|---|---|---|
| 1. ChatGPT-Subscription | "Wir nutzen KI" = Mitarbeiter haben Pro-Account | Marginal, nicht messbar |
| 2. API-Key + Wrapper | Custom UI, gleiches Modell, kein Kontext | "Schöneres ChatGPT" |
| 3. RAG-Chatbot | Vector Store über PDFs, ein System Prompt | Beantwortet FAQs, automatisiert nichts |
| 4. Agentic Setup | Sub-Agents, Tools, Operations-Zugriff | Automatisiert echte Workflows |
Die Phasen 1–3 sind das, worüber fast alle reden. Phase 4 ist die, in der echtes Geld bewegt wird – und die kaum jemand sauber baut.
Was "Enterprise-Grade Agentic" wirklich bedeutet
Ein produktionsreifes agentisches Setup besteht aus vier Bausteinen, die in dieser Reihenfolge entstehen müssen:
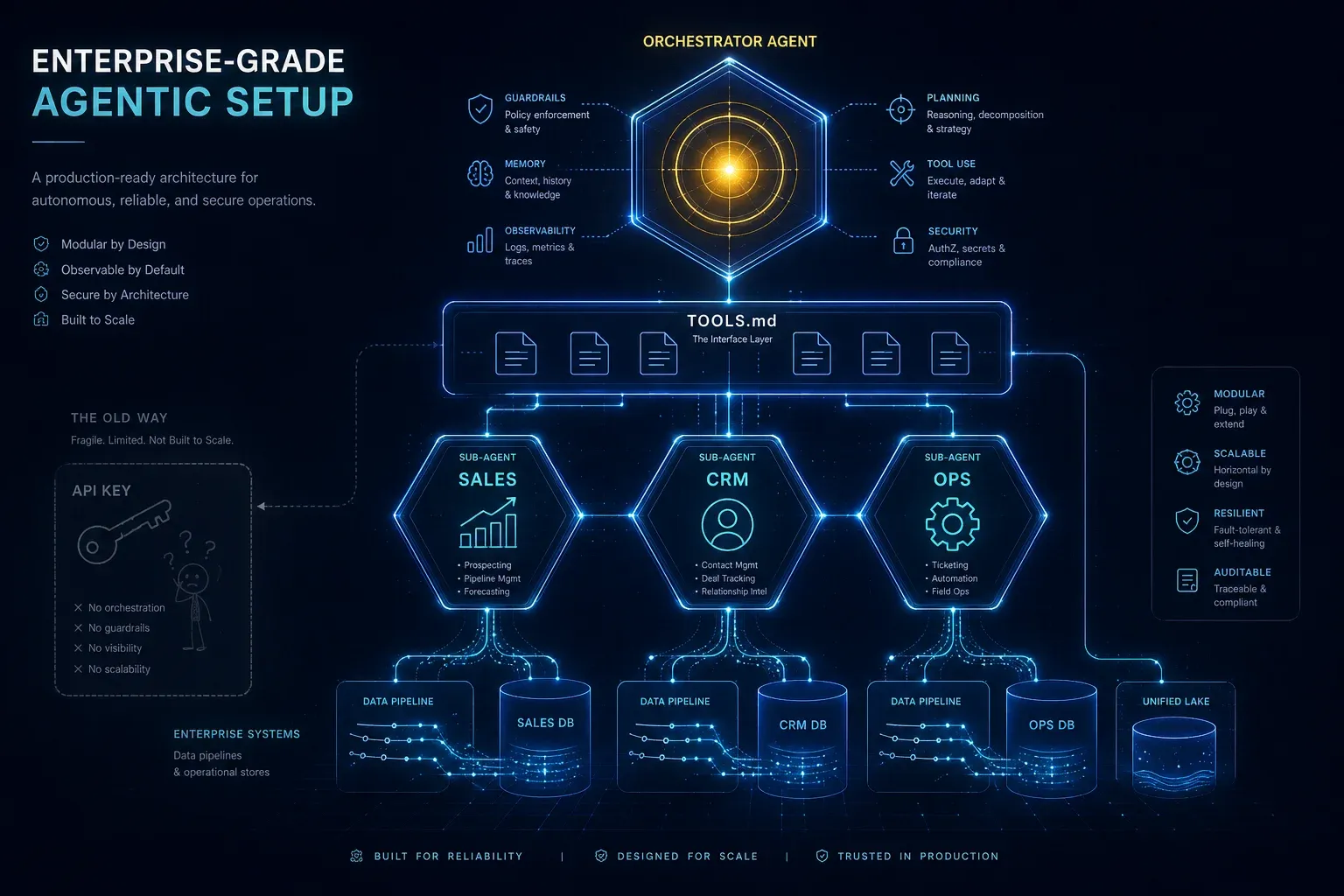
1. Sub-Agent-Architektur statt Monolith
Ein einziger "Allwissender Agent" ist eine Anti-Pattern. Frontier-Modelle werden mit jedem Tool, jedem Context-Eintrag und jeder Instruction langsamer und teurer. Die Lösung: Spezialisierung.
┌─────────────────┐
│ Orchestrator │
│ (Router) │
└────────┬────────┘
│
┌─────────────────────┼─────────────────────┐
│ │ │
┌──────▼──────┐ ┌──────▼──────┐ ┌──────▼──────┐
│ Sales Agent │ │ CRM Agent │ │ Ops Agent │
│ Tools: 4 │ │ Tools: 6 │ │ Tools: 8 │
│ SP: 2k tok │ │ SP: 3k tok │ │ SP: 4k tok │
└─────────────┘ └─────────────┘ └─────────────┘Jeder Sub-Agent:
- hat eine klare Mission (z. B. "Lead-Qualifikation in monday CRM")
- lädt nur die Tools, die er braucht
- hat einen System Prompt unter 5k Tokens statt eines aufgeblähten 30k-Monsters
- kann von Usern oder anderen Agents aufgerufen werden
2. TOOLS.md als Single Source of Truth
Ein Tool ohne Doku ist ein Tool, das der Agent halluziniert. Die TOOLS.md ist das, was Anthropic in Claude Code, Cursor in seinen Rules und unsere internen Stacks in jedem Projekt etabliert haben:
# TOOLS.md
## search_crm_contacts
Sucht Kontakte in monday CRM nach Name, Firma oder E-Mail.
**When to use:**
- User fragt nach einem konkreten Kontakt oder Account
- Vor jedem `update_contact`-Call zur ID-Auflösung
**When NOT to use:**
- Für Listings ohne Filter (nutze `list_pipeline` stattdessen)
- Für historische Daten älter als 90 Tage
**Args:** query (string), limit (int, default 10)
**Returns:** Array of {id, name, company, email, owner}Diese Datei wird bei jedem Session-Start geladen, bevor das Modell überhaupt denkt. Resultat: keine halluzinierten Tool-Calls, keine teuren Retry-Loops, deterministisches Verhalten.
3. System-Prompt-Architektur: dünn, dediziert, deterministisch
Ein guter System Prompt für einen Sub-Agent hat eine klare Struktur:
- Rolle & Mission (3–5 Sätze) – wer bist du, was tust du nicht
- Tool-Verweis ("Konsultiere TOOLS.md vor jedem Call")
- Eskalationspfade (wann an Orchestrator zurück, wann an Mensch)
- Output-Contract (Format, das andere Agents/Systeme parsen können)
Was nicht in den System Prompt gehört: 4000 Token Beispiele, kompletter Style Guide, jedes Edge Case. Das gehört in separate Dokumente, die der Agent on-demand lädt.
4. Operations-Zugriff statt Demo-Daten
Der Unterschied zwischen Demo und Wertschöpfung: echter Schreibzugriff auf operative Systeme – CRM, ERP, Ticketing, Datenbank, File Storage. Mit:
- Granularen Permissions pro Sub-Agent
- Audit-Logs für jeden Write
- Rollback-fähigen Operationen
- Human-in-the-Loop für Hochrisiko-Aktionen
Warum Inference-Kosten Sub-Agents erzwingen
Frontier-Modelle werden teurer, nicht billiger. Claude Opus 4.7, GPT-5.2, Gemini 3 Ultra – alle bewegen sich Richtung mehrere Dollar pro Million Output-Tokens. Wer einen einzigen 30k-Token-System-Prompt mit 50 Tools bei jedem Request lädt, zahlt das in jedem Turn.
Die Mathematik:
| Setup | Tokens pro Request | Kosten pro 10k Requests (Opus 4.7) |
|---|---|---|
| Monolith-Agent (30k Prompt + Tools) | ~32k Input | ~$480 |
| Spezialisierter Sub-Agent (4k Prompt) | ~5k Input | ~$75 |
| Ersparnis | ~85 % | ~$405 pro 10k Calls |
Bei einem Mid-Market-Unternehmen mit 50.000 Agent-Calls pro Monat sind das ~$2.000/Monat eingespart – nur durch Architektur, ohne Qualitätsverlust. Mehr dazu in unserem Deep-Dive zum Agent-Runtime-Vergleich.
Tool-Loading pro Session: das übersehene Pattern
Der typische Anfängerfehler: Alle Tools in jedem Request mitschicken. Der professionelle Pattern:
- Session-Start: Sub-Agent wird instanziiert mit System Prompt +
TOOLS.md-Index (nicht den Tools selbst) - First Turn: Agent entscheidet, welche Tools er für diese Aufgabe wirklich braucht
- Tool-Hydration: Nur die selektierten Tool-Definitionen werden in den Context geladen
- Execution: Brain-Call mit minimalem, fokussiertem Context
Resultat: schnellere Time-to-First-Token, niedrigere Kosten, weniger Tool-Verwechslungen. Das ist der Unterschied zwischen "KI antwortet in 8 Sekunden" und "KI antwortet in 1,5 Sekunden" – und in einem operativen Setup ist das der Unterschied zwischen Adoption und Ablehnung.
Agent-zu-Agent: der Multiplikator
Der eigentliche Hebel entsteht, wenn Agents andere Agents aufrufen können. Beispiel aus einer realen Implementierung bei einem unserer Kunden:
User: "Schick dem Lead von gestern den passenden Pitch."
→ Orchestrator routet an Sales-Agent
→ Sales-Agent ruft CRM-Agent: "Wer war der Lead von gestern?"
→ CRM-Agent: {id, name, company, branch, deal_size}
→ Sales-Agent ruft Content-Agent: "Pitch-Variante für SaaS, Deal-Size €50k"
→ Content-Agent: {pitch_text, attachments}
→ Sales-Agent ruft Email-Agent: "Sende mit Pitch X an Lead Y"
→ Email-Agent: {sent: true, message_id}
→ Orchestrator: "Erledigt. E-Mail an Anna Müller (Acme GmbH) raus."Drei Sub-Agents, vier Tool-Calls, eine User-Anfrage in natürlicher Sprache. Das ist der Punkt, an dem KI nicht mehr "antwortet" – sondern operiert. Genau dieses Pattern beschreibt auch Ales Drabeks Dark Software Factory bei Groupon: JIRA-Ticket-Status als Trigger, Sub-Agents als Worker, Human Gate vor Merge.
Der Stack, mit dem wir das bauen
Ohne Tool-Religion, hier ist, was bei uns und unseren Kunden produktiv läuft:
- Orchestration: Claude Code (Managed Agents) oder LangGraph für Custom-Logik
- Sub-Agent-Runtime: Claude Sonnet 4.5 / Haiku für günstige Sub-Tasks, Opus für Routing
- Tool-Standard: MCP (Model Context Protocol) als Schnittstelle
- Operations-Layer: monday.com als Company-OS, Supabase als operative DB, n8n/Make für Edge-Cases
- Observability: Langfuse oder Helicone für Tracing, Cost-Tracking, Eval
Mehr dazu in unseren Vergleichen zu Agent Runtimes und Agent Sandboxing. Wer Engineering-Workflows agentisch automatisieren will, sollte auch unseren Deep-Dive zu monday Dev als unterschätztem Dev-Tool und die Migration von Jira zu monday Dev als Context-Layer für Coding-Agents lesen.
Die Reifegrad-Checkliste
Bevor du das nächste KI-Pilotprojekt startest, prüfe ehrlich, wo dein Setup steht:
- Mindestens zwei spezialisierte Sub-Agents statt eines Monolithen
- TOOLS.md mit "When to use / When NOT to use" für jedes Tool
- System Prompts pro Sub-Agent unter 5k Tokens
- Tool-Hydration pro Session statt Vollast in jedem Turn
- Mindestens ein Schreibzugriff auf ein operatives System (CRM/ERP)
- Audit-Log für jede Write-Operation
- Agent-zu-Agent-Calls für mindestens einen Workflow
- Cost-Tracking & Eval-Loop in Production
Wer weniger als sechs Häkchen hat, ist im Demo-Stadium. Wer alle hat, hat echte Operations-Automatisierung.
Fazit: Agentic Setup ist nicht optional
Mit steigenden Inference-Kosten der Frontier-Modelle ist die Wahl nicht mehr "monolithischer Agent oder spezialisierte Sub-Agents". Die Wahl ist "agentische Architektur oder KI als teures Spielzeug".
Wer 2026 noch glaubt, ein API-Key reicht für KI-Wertschöpfung, baut nichts auf – er bezahlt nur OpenAI-Rechnungen. Wer Sub-Agents, TOOLS.md, dedizierte System Prompts und Operations-Zugriff sauber aufsetzt, automatisiert das, wovon andere noch in der Öffentlichkeit träumen.
Der Gap ist real. Und er wird größer, nicht kleiner.
Weiterlesen:
- AI Agentic First bei Groupon: Drabeks Dark Software Factory in Production
- monday Dev: Das unterschätzte Dev-Tool 2026 – Context-Layer für Coding-Agents
- Sprint Planning mit monday Dev – maschinenlesbare Tickets als Voraussetzung für Agents
- Jira zu monday Dev migrieren – sauberes Backlog vor dem ersten Agent
→ Beratung zu Enterprise Agentic Setups buchen | → Agentic Engineering Übersicht
Häufig gestellte Fragen
Sub-Agents, TOOLS.md, Tool-Loading pro Session und die Reifegrad-Checkliste – kurz beantwortet.
Verwandte Artikel
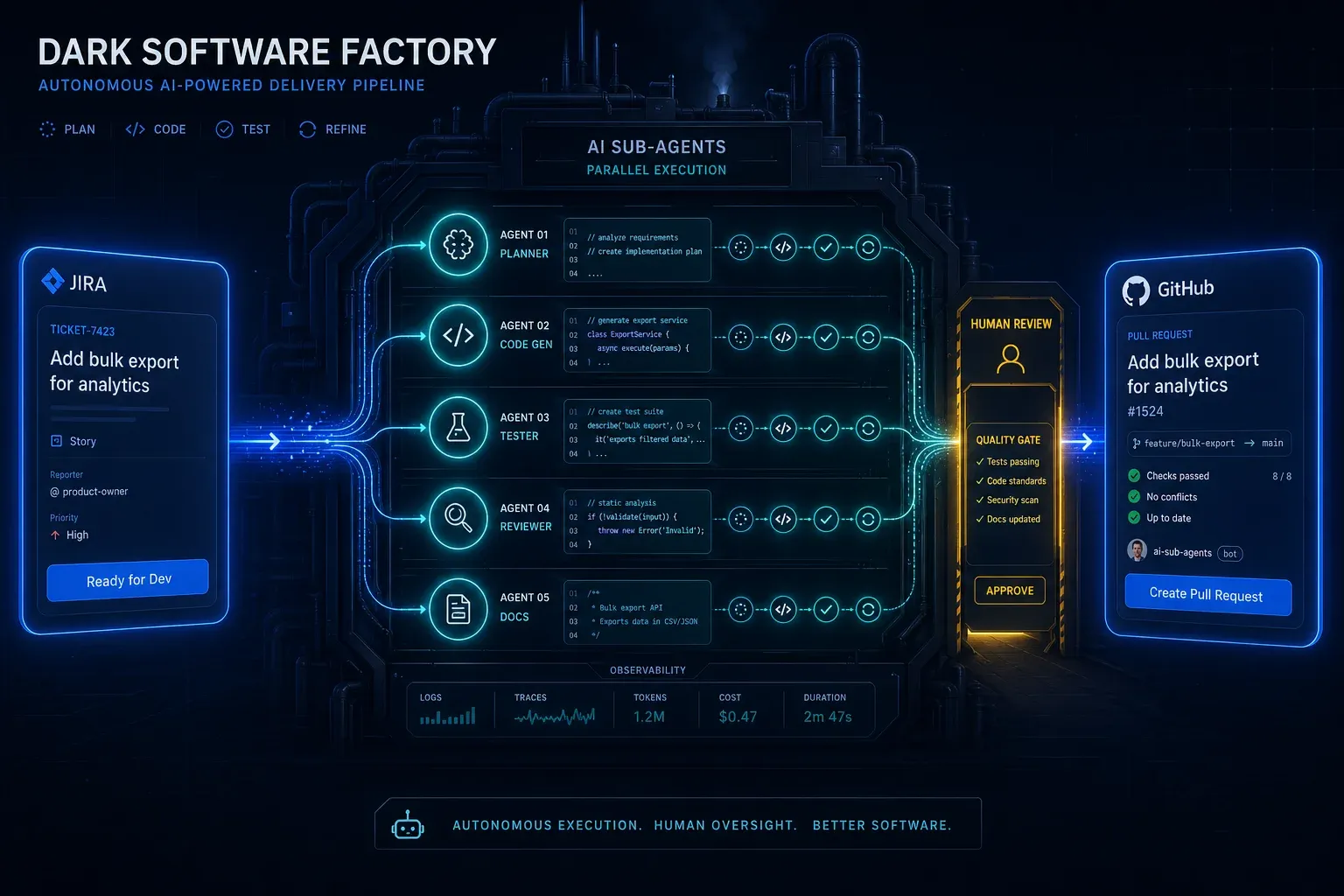
AI Agentic First bei Groupon: Was Ales Drabeks Dark Software Factory uns lehrt
Ales Drabek, CTIO bei Groupon, hat zwei Patterns in Production: Dark Software Factory und Speedboats. Was das über AI Ag…
Weiterlesen
Ponytail: Warum der beste Code der Code ist, den du nie geschrieben hast
Ein Dev hat Ponytail gebaut – weil seine AI-Agenten 500 Zeilen für ein 5-Zeilen-Problem schrieben. Das Ergebnis: 80-94% …
Weiterlesen
Agent Skills werden Industrie-Standard: Was Teams jetzt wissen müssen
Agent Skills sind wiederverwendbare Fähigkeiten für KI-Agenten – und werden zum neuen Standard. Was sie von MCP untersch…
Weiterlesen
monday.com öffnet die Türen für KI-Agenten: Was hinter agents-signup steckt
monday.com hat einen eigenen Signup-Flow für KI-Agenten gebaut – mit HATCHA, MCP und Instant API Key. Warum das mehr ist…
Weiterlesen
Googles Agent Marketplace ist live – und monday.com ist von Tag eins dabei
Google öffnet Gemini Enterprise für Partner-AI-Agenten – und monday.com ist von Anfang an drin. Was das für Enterprise-W…
Weiterlesen
Globster: monday.com bringt persönliche KI-Agenten – auf NemoClaw von NVIDIA
monday agent labs hat mit Globster ein neues Produkt vorgestellt: persönliche KI-Agenten auf Basis von OpenClaw, abgesic…
Weiterlesen
Copilot vs. OpenClaw vs. Claude: Enterprise AI Agents im Vergleich 2026
Drei Philosophien, ein Ziel: KI-Agenten im Enterprise. Microsoft Copilot (Plattform), OpenClaw (Open Source), Claude (AP…
Weiterlesen
Agentalent.ai: monday.com startet den ersten Marktplatz für KI-Agenten
monday.com launcht Agentalent.ai – einen Marktplatz, auf dem Unternehmen KI-Agenten für echte Business-Rollen 'einstelle…
Weiterlesen
AI Agent Ops: Agenten in Produktion überwachen, auditieren und kontrollieren
Governance ist die Strategie – Agent Ops ist die Umsetzung. Wie man autonome KI-Agenten in Produktion überwacht, auditie…
Weiterlesen