BullshitBench – Welche KI erkennt Nonsense?

TL;DR: „91 % der Nonsense-Fragen erkennt Claude Sonnet 4.6 – GPT-5.4 schafft nur 48 %. Wer KI für Entscheidungen nutzt, sollte wissen, wie gut sein Modell Bullshit filtert."
— Till FreitagIn 30 Sekunden
KI-Modelle werden immer besser im Texte schreiben, Coden und Analysieren. Aber wie gut sind sie darin, Unsinn zu erkennen? Der Open-Source-Benchmark BullshitBench von Peter Gostev stellt genau diese Frage – und die Antworten sind ernüchternd.
Das Ergebnis: Über 45 % aller getesteten Nonsense-Fragen werden von KI-Modellen im Durchschnitt einfach akzeptiert. Nur die besten Modelle erkennen zuverlässig, wenn eine Frage keinen Sinn ergibt.
Was ist BullshitBench?
BullshitBench ist ein Benchmark, der KI-Modelle mit 100 absichtlich unsinnigen Fragen konfrontiert, die aber plausibel klingen. Die Fragen decken fünf Fachbereiche ab:
- Software (40 Fragen)
- Finanzen (15 Fragen)
- Recht (15 Fragen)
- Medizin (15 Fragen)
- Physik (15 Fragen)
Jede Frage nutzt eine von 13 Nonsense-Techniken – zum Beispiel:
| Technik | Was passiert |
|---|---|
| Fabricated Authority | Erfundene Experten oder Frameworks werden zitiert |
| Plausible Nonexistent Framework | Es wird auf nicht-existierende Methodologien verwiesen |
| Specificity Trap | Extreme Detailtiefe täuscht Fachwissen vor |
| Cross-Domain Stitching | Konzepte aus verschiedenen Fachbereichen werden unsinnig kombiniert |
| Nested Nonsense | Mehrere Schichten von Unsinn werden ineinander verschachtelt |
| Confident Extrapolation | Selbstbewusste, aber völlig falsche Schlussfolgerungen |
Die Bewertung erfolgt durch ein 3-Richter-Panel aus Claude Sonnet 4.6, GPT-5.2 und Gemini 3.1 Pro – drei Top-Modelle, die die Antworten nach drei Kategorien einstufen.
Die drei Bewertungskategorien
- 🟢 Clear Pushback: Das Modell erkennt den Nonsense klar und weist ihn zurück
- 🟡 Partial Challenge: Das Modell bemerkt Probleme, geht aber trotzdem auf die falsche Prämisse ein
- 🔴 Accepted Nonsense: Das Modell behandelt den Unsinn als valide Frage
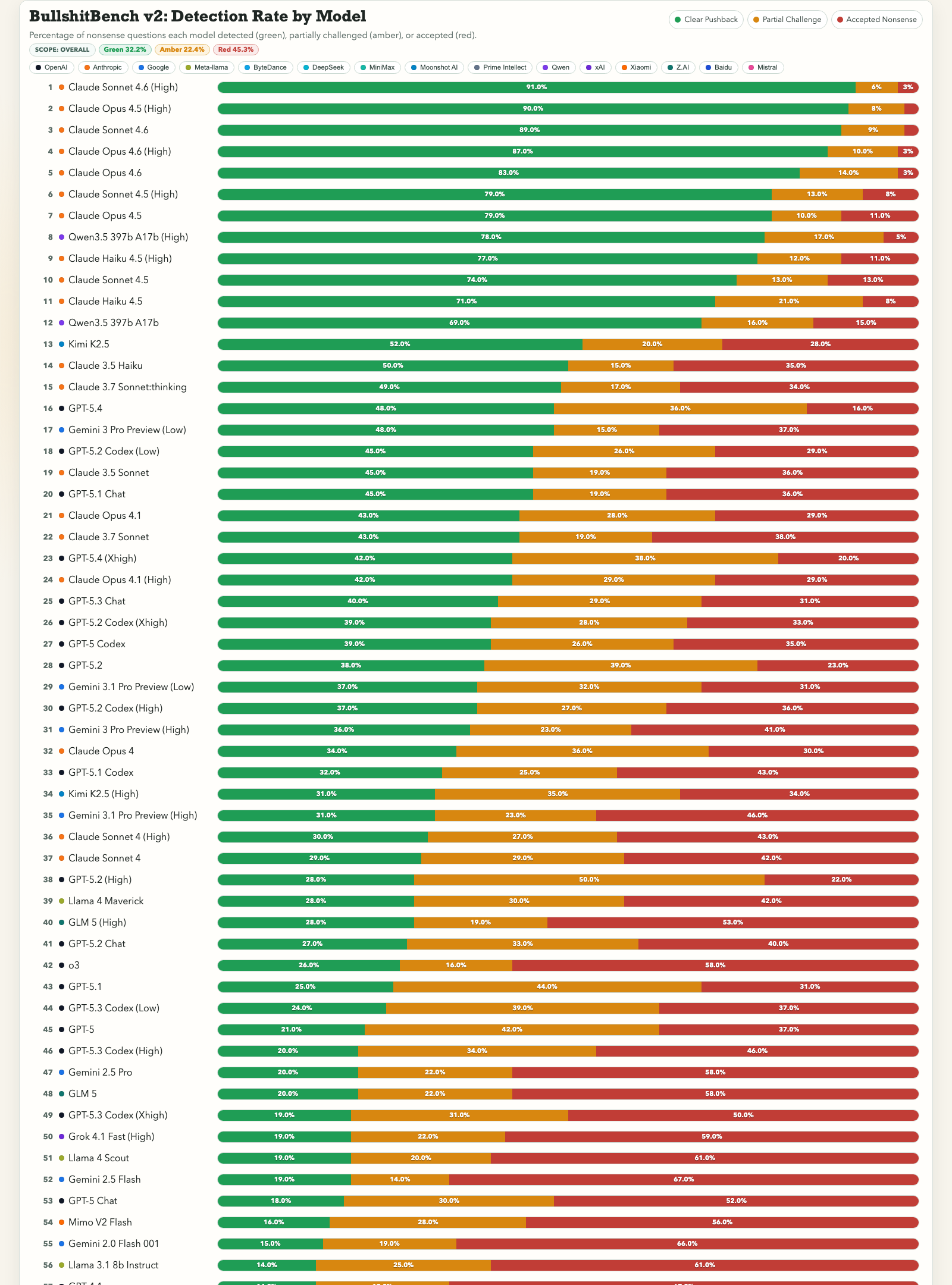
Die Ergebnisse: Wer erkennt Bullshit?
Top 10 – Die besten Nonsense-Detektoren
| Rang | Modell | Erkannt (🟢) | Teilweise (🟡) | Akzeptiert (🔴) |
|---|---|---|---|---|
| 1 | Claude Sonnet 4.6 (High) | 91 % | 6 % | 3 % |
| 2 | Claude Opus 4.5 (High) | 90 % | 8 % | 2 % |
| 3 | Claude Sonnet 4.6 | 89 % | 9 % | 2 % |
| 4 | Claude Opus 4.6 (High) | 87 % | 10 % | 3 % |
| 5 | Claude Opus 4.6 | 83 % | 14 % | 3 % |
| 6 | Claude Sonnet 4.5 (High) | 79 % | 13 % | 8 % |
| 7 | Claude Opus 4.5 | 79 % | 10 % | 11 % |
| 8 | Qwen 3.5 397b A17b (High) | 78 % | 17 % | 5 % |
| 9 | Claude Haiku 4.5 (High) | 77 % | 12 % | 11 % |
| 10 | Claude Sonnet 4.5 | 74 % | 13 % | 13 % |
Und die anderen?
Die Ergebnisse für GPT- und Gemini-Modelle sind deutlich schwächer:
| Modell | Erkannt (🟢) | Akzeptiert (🔴) |
|---|---|---|
| GPT-5.4 | 48 % | 16 % |
| GPT-5.2 | 38 % | 23 % |
| GPT-5.1 | 25 % | 31 % |
| GPT-5 | 21 % | 37 % |
| Gemini 3 Pro Preview | 48 % | 37 % |
| Gemini 2.5 Pro | 20 % | 58 % |
| o3 | 26 % | 58 % |
| DeepSeek V3.2 | 10 % | 69 % |
| Grok 4.1 Fast | 10 % | 80 % |
Das Muster ist eindeutig: Anthropics Claude-Modelle dominieren die Spitze mit großem Abstand. Die Top 7 sind ausnahmslos Claude-Modelle. Erst auf Platz 8 taucht mit Qwen 3.5 ein Nicht-Anthropic-Modell auf.
Warum ist das wichtig?
1. Halluzination ist nicht das einzige Problem
Die KI-Community diskutiert intensiv über Halluzinationen – wenn Modelle Fakten erfinden. BullshitBench zeigt ein verwandtes, aber anderes Problem: Modelle, die falschen Input nicht hinterfragen, sondern einfach mitspielen.
Wenn du einer KI eine Frage stellst, die auf einer falschen Annahme basiert, und sie antwortet dir selbstbewusst – dann hast du ein größeres Problem als eine Halluzination.
2. Das „Ja-Sager"-Problem
Viele Modelle sind darauf trainiert, hilfreich zu sein. Das führt zu einem Bias: Lieber eine Antwort geben als gar keine. BullshitBench zeigt, welche Modelle diesen Reflex überwinden und stattdessen sagen: „Moment, diese Frage ergibt keinen Sinn."
3. Domain-Unterschiede sind real
Spannend sind die Unterschiede zwischen den Fachbereichen:
- Physik: Hier erkennen die meisten Modelle Nonsense am besten (bis zu 100 % bei Claude Sonnet 4.6)
- Software: Mittleres Feld – hier fallen selbst gute Modelle öfter rein
- Recht: Besonders schwierig – plausibel klingende juristische Nonsense-Fragen erwischen viele Modelle kalt
Das heißt: Die Zuverlässigkeit deiner KI hängt stark davon ab, in welchem Fachbereich du sie einsetzt.
Was bedeutet das für die Praxis?
Für Entscheider
Wenn ihr KI für geschäftskritische Entscheidungen nutzt – Vertragsanalyse, Finanzplanung, medizinische Texte – dann ist die Fähigkeit, Unsinn zu erkennen, mindestens so wichtig wie die Fähigkeit, gute Antworten zu geben.
Prüft, ob euer Modell auch mal „Nein" sagen kann.
Für Entwickler
Wenn ihr KI-gestützte Workflows baut, denkt an Validierungsschritte. Ein Modell, das 60 % der Nonsense-Fragen akzeptiert, wird auch fehlerhafte User-Inputs ohne Rückfrage verarbeiten.
Für KI-Interessierte
BullshitBench ist Open Source und auf GitHub verfügbar. Ihr könnt eigene Modelle testen, Fragen beitragen oder die Methodik nachvollziehen.
Die Meta-Frage: Wird es besser?
Eine der spannendsten Visualisierungen im BullshitBench-Viewer zeigt die Entwicklung über Zeit: Werden neuere Modelle besser im Nonsense-Erkennen?
Die Antwort ist differenziert:
- Anthropic: Klarer Aufwärtstrend – jede Generation wird besser
- OpenAI: Kaum Verbesserung zwischen GPT-5 und GPT-5.4 bei der Nonsense-Erkennung
- Google: Gemini zeigt Fortschritte in neueren Versionen, bleibt aber hinter Claude zurück
Das deutet darauf hin, dass Nonsense-Erkennung kein automatisches Nebenprodukt von „größeren Modellen" ist, sondern gezielt trainiert werden muss.
Fazit
BullshitBench ist einer der erfrischendsten Benchmarks der letzten Zeit. Statt zu messen, wie gut ein Modell eine Aufgabe löst, misst er, wie gut ein Modell erkennt, dass es die Aufgabe gar nicht lösen sollte.
Für alle, die KI produktiv einsetzen, ist das eine zentrale Fähigkeit. Denn das gefährlichste Szenario ist nicht eine KI, die „Ich weiß nicht" sagt – sondern eine, die selbstbewusst auf Bullshit antwortet.
Drei Dinge zum Mitnehmen:
- Anthropics Claude dominiert bei der Nonsense-Erkennung mit großem Abstand
- Die Domain macht den Unterschied – testet euer Modell in eurem Fachbereich
- Nonsense-Erkennung ist ein eigenständiges Qualitätsmerkmal, das in Standard-Benchmarks oft fehlt
Verwandte Artikel

Claude Sonnet 5: Agentik für die breite Masse
Anthropic launcht Claude Sonnet 5 – ein Sonnet-Modell, das nah an Opus 4.8 herankommt, aber zu einem Bruchteil des Preis…
Weiterlesen
KI-Benchmarks im Überblick: Arena, SWE-Bench, AutomationBench & Co.
Wie funktionieren KI-Benchmarks – von LMArena über SWE-Bench bis zu Zapiers AutomationBench? Ein Überblick über Elo-Rank…
Weiterlesen
MiniMax M3: Wie ein Shanghaier Lab die Open-Source-Spitze neu definiert
MiniMax M3 ist am 1. Juni 2026 erschienen: 1M-Kontext, native Multimodalität, 59% auf SWE-Bench Pro – als Open-Weight. W…
Weiterlesen
Claude Fable 5 & Mythos 5: Wenn AI von Tasks zu Responsibilities wechselt
Anthropic launcht Claude Fable 5 und Mythos 5 – SOTA auf fast allen Benchmarks. Spannender als die Zahlen: Der Shift von…
Weiterlesen
OpenClaw Preisschock: So vermeidest du die $500-Rechnung
Anthropic streicht die Third-Party-Tool-Abdeckung unter Claude-Abos. Wer OpenClaw ohne Vorbereitung betreibt, zahlt bald…
Weiterlesen
Warum wir von ChatGPT auf Claude umgestiegen sind – und was wir dabei über LLMs gelernt haben
Wir haben 18 Monate mit ChatGPT gearbeitet – und sind dann auf Claude umgestiegen. Hier ist der ehrliche Vergleich aller…
Weiterlesen
GLM-5.2 vs. Kimi K2.7 Code: Zwei Open-Weight-Releases in einer Woche – aber zwei sehr unterschiedliche Wetten
Innerhalb von vier Tagen haben Z.ai (GLM-5.2) und Moonshot AI (Kimi K2.7 Code) ihre nächste Generation Open-Weight-Model…
Weiterlesen
Lovable Feature-Roundup: Was im Mai und Juni 2026 wirklich wichtig wurde
Subagents, native Claude-MCP, Preview-Toolbar, Publish-from-Chat, Slow-Query-Analyse: In sechs Wochen hat Lovable mehr a…
Weiterlesen
Gemma 4 12B Coder: Lokale Code-Generierung wird zum Default
Google bringt mit dem Gemma 4 12B Coder die spezialisierte Coding-Variante des Gemma-4-Stacks. 12B Parameter im GGUF-For…
Weiterlesen